
Most AI model releases follow a familiar pattern: bigger numbers on benchmarks, a new version suffix, a press release. NVIDIA’s Nemotron 3 Super, released on 11 March 2026, is different in ways that matter for how businesses think about deploying AI at scale.
This isn’t primarily a model for answering questions or writing copy. It’s specifically engineered for agentic AI — systems where an AI works autonomously through multi-step tasks, calling tools, writing and executing code, managing long workflows, and coordinating with other AI agents. That distinction is important, and it shapes everything about how the model was designed.
At 120 billion total parameters but only 12 billion active at any given moment, Nemotron 3 Super is built to solve two problems that make agentic AI genuinely hard to deploy in production: the cost of running a large model continuously across long tasks, and the tendency of AI agents to lose track of what they were originally trying to do. Here’s a clear breakdown of what’s new, what the benchmark numbers mean, and what it signals for businesses building or evaluating AI automation in Singapore and across Southeast Asia.
The Two Problems Nemotron 3 Super Is Built to Solve
Problem 1: The Thinking Tax
When you build a multi-agent system — multiple AI models coordinating to complete a complex task — the token volumes involved are dramatically higher than in standard chat applications. NVIDIA estimates that multi-agent systems generate up to 15 times the tokens of a typical conversation, because agents must re-send context, tool outputs, and reasoning steps at each turn.
The obvious solution of using the most powerful reasoning model for every sub-task is what NVIDIA calls the thinking tax: using a heavyweight model for simple steps makes the overall system too slow and expensive for practical deployment. You need a model that’s genuinely capable on complex tasks but efficient enough to run continuously.
Nemotron 3 Super addresses this with a hybrid mixture-of-experts (MoE) architecture. Despite having 120 billion total parameters, only 12 billion are active at any moment — the model routes each token to a relevant subset of specialist modules rather than running the full parameter set every time. The result is over 5x throughput improvement versus the previous Nemotron Super, while maintaining accuracy on complex tasks.
Problem 2: Context Explosion and Goal Drift
The second problem is subtler but equally serious for production agentic deployments. As an agent works through a long task — processing a large codebase, analysing a stack of documents, maintaining a multi-hour workflow — the sheer volume of context it must track grows rapidly. Most transformer-based models struggle here: their context handling becomes less precise as the window fills, and agents gradually lose alignment with the original objective. NVIDIA calls this goal drift.
Nemotron 3 Super tackles this with a native 1 million token context window, made practical by its hybrid Mamba-Transformer backbone. Mamba layers handle the majority of sequence processing using state space models (SSMs), which have linear rather than quadratic complexity with respect to sequence length. This is what makes a 1 million token context window achievable without prohibitive memory requirements — not just a theoretical maximum but something agents can actually use in practice.
What Makes the Architecture Different
Hybrid Mamba-Transformer Backbone
Rather than using a pure transformer architecture, Nemotron 3 Super interleaves three distinct layer types, each handling what it does best.
Mamba-2 layers handle the bulk of sequence processing. Because SSMs scale linearly rather than quadratically with sequence length, they’re what makes the 1M token context window practical. When an agent needs to reason over an entire codebase or a long document history, Mamba layers keep the memory footprint manageable.
Transformer attention layers are placed at key depths within the architecture. Pure SSMs can struggle with precise associative recall — finding one specific fact in a long context when conflicting information surrounds it. The transformer layers preserve this capability, ensuring high-fidelity retrieval even in dense, noisy contexts.
MoE layers scale the effective parameter count without the cost of dense computation. Only a subset of expert modules activates per token, keeping latency low even when many agents run concurrently on shared infrastructure.
Latent MoE — More Experts, Same Cost
Standard MoE architectures route tokens directly from the model’s full hidden dimension to expert modules. As models grow, this routing step becomes a bottleneck. Nemotron 3 Super introduces latent MoE: token embeddings are compressed into a low-rank latent space before routing decisions are made. Expert computation happens in this smaller dimension, and results are projected back afterward.
In practice, this means the model can consult 4 times as many specialists for the exact same computational cost as routing to one. In agentic settings where a single workflow might span tool calls, code generation, data analysis, and reasoning within a few turns, this granularity of specialisation is genuinely valuable — distinct experts can be activated for Python syntax versus SQL logic versus financial calculation, only when strictly needed.
Multi-Token Prediction
Most language models are trained to predict one token at a time. Nemotron 3 Super uses multi-token prediction (MTP), where specialised prediction heads forecast several future tokens simultaneously from each position.
This has two concrete effects. During training, predicting multiple future tokens forces the model to internalise longer-range logical dependencies — it must learn coherent sequences rather than just plausible next words. At inference, MTP enables built-in speculative decoding, where multiple future tokens are generated in one forward pass and verified in parallel. NVIDIA reports up to 3x wall-clock speedups for structured generation tasks like code and tool calls, without requiring a separate draft model.
Native NVFP4 Pretraining
Most quantised models start at full precision and get compressed after training — which introduces accuracy loss. Nemotron 3 Super is pretrained natively in NVFP4, NVIDIA’s 4-bit floating-point format optimised for Blackwell GPUs. The model learns to be accurate within 4-bit arithmetic constraints from the very first gradient update, rather than adapting to them after the fact.
NVIDIA reports 4x faster inference on NVIDIA B200 compared to FP8 on H100, while maintaining accuracy. For businesses running AI inference at scale, this has direct cost implications — the same workload on newer hardware runs significantly faster and cheaper.
How It Was Trained
Nemotron 3 Super’s training pipeline runs in three sequential phases, each building on the last.
Pretraining ran on 25 trillion tokens using NVFP4, with a corpus of 10 trillion unique curated tokens seen multiple times across the run, plus additional compute focused on reasoning and coding tasks. The model builds broad world knowledge and language understanding at this stage.
Supervised fine-tuning followed, using approximately 7 million samples drawn from a broader pool of 40 million covering reasoning, instruction following, coding, safety, and multi-step agent tasks. This shapes the model’s behaviour across the task types it will encounter in deployment and gives the subsequent reinforcement learning phase a stable starting point.
Reinforcement learning then refines behaviour against verifiable outcomes across 21 environment configurations using NVIDIA’s NeMo Gym and NeMo RL frameworks. These aren’t single-turn question-answer tasks — they evaluate the model’s ability to perform sequences of actions, generate correct tool calls, write functional code, and produce multi-part plans that satisfy verifiable criteria. The RL phase generated approximately 1.2 million environment rollouts during training.
This trajectory-based reinforcement learning approach is what produces a model that behaves reliably under multi-step workflows, reduces reasoning drift, and handles the structured operations common in real agentic pipelines — as opposed to a model that performs well on static benchmarks but degrades under long autonomous runs.
The Benchmark Numbers
Nemotron 3 Super’s benchmark results are strong, particularly on the agentic and tool-use tasks it was designed for. The numbers below compare it against Qwen 3.5 122B, a similarly sized open model.
| Benchmark | Nemotron 3 Super | Qwen 3.5 122B | What it tests |
|---|---|---|---|
| IFBench (Instruction Following) | 94.4% | 73.4% | Following complex instructions |
| HMMT Feb25 (Math) | 90.4% | 46.3% | Advanced mathematics |
| SWE-Bench (Coding) | 60.5% | 41.9% | Real software engineering tasks |
| HLE (Science) | 66.4% | 26.8% | Expert-level science reasoning |
| Tau Bench v2 (Tool Use) | 91.8% | 22.3% | Real-world tool calling |
| RULER @ 1M (Long Context) | 91.3% | — | 1 million token context recall |
The Tau Bench v2 result — 91.8% on tool use, against 22.3% for Qwen — is the most striking. Tool use is directly relevant to agentic deployment: it measures how reliably a model calls the right tools with the right parameters across multi-step tasks. A model that scores 91.8% on this in testing is meaningfully more deployable in production agentic workflows than one scoring 22.3%.
The RULER @ 1M result (91.3%) confirms that the 1 million token context window is functional, not just nominal — the model maintains high recall accuracy across a full million-token context, which is what matters for agents working across large codebases or long document collections.

The Super + Nano Deployment Pattern
One of the more practically useful ideas in the NVIDIA announcement is the Super + Nano deployment pattern — a tiered architecture for agentic systems that matches model capacity to task complexity.
Nemotron 3 Nano (released in December 2025) handles targeted, individual steps within a workflow — the simple, high-frequency tasks where speed and cost matter more than depth. Nemotron 3 Super handles the complex, multi-step tasks that require deeper planning and reasoning. For the most demanding expert-level work, proprietary frontier models like GPT-5.4 or Claude can be called in.
In software development, for example: simple merge requests go to Nano, complex codebase analysis and multi-file refactoring go to Super, and tasks requiring frontier-level reasoning can be escalated to a proprietary model. This tiered approach is how businesses can build production agentic systems that are both capable and economically viable — not routing everything through the most expensive model available.
This mirrors a pattern we’ve seen emerging across the industry. We wrote recently about GPT-5.4’s tool search capability, which similarly reduces the cost of running large models across complex tool ecosystems. The direction is consistent: agentic AI is becoming more modular, more tiered, and more practically deployable — not just more capable in isolation.
Fully Open — What That Means in Practice
Nemotron 3 Super is fully open: weights, datasets, and training recipes are all publicly available. This is significant for businesses in Southeast Asia where data sovereignty, privacy, and on-premise deployment are often hard requirements.
Full model weights are available on Hugging Face and through NVIDIA NIM. The NVIDIA Nemotron Open Model License gives enterprises the flexibility to deploy on their own infrastructure, maintaining full data control. Ready-to-use deployment cookbooks cover vLLM, SGLang, and NVIDIA TensorRT LLM. Fine-tuning cookbooks cover LoRA/SFT for domain adaptation and GRPO/DAPO for advancing agentic reasoning capabilities.
For businesses in Singapore and across Southeast Asia that need to customise AI models for local languages, domain-specific knowledge, or compliance requirements, the availability of full weights and training recipes is meaningfully different from API-only access to a proprietary model. You can adapt it, fine-tune it, and run it entirely within your own infrastructure.
What This Means for Businesses in Southeast Asia
Nemotron 3 Super is a technical release aimed primarily at developers building agentic systems. But the implications for business AI strategy are real, and worth thinking through clearly.
- undefined The combination of efficient architecture, 1M token context, and strong tool-use performance addresses the specific problems that have made agentic deployments fragile in practice. If you’ve evaluated agentic AI before and found it too slow, too expensive, or too prone to losing the thread — the landscape is shifting.
- Open weights change the calculus for regulated industries. Finance, healthcare, and legal sectors in Singapore, Jakarta, and Kuala Lumpur operate under data governance requirements that make API-only AI tools complicated to use. A fully open model with enterprise licensing can be deployed on-premise, fine-tuned on proprietary data, and audited end-to-end.
- The tiered deployment model is the right framework for cost-effective AI automation. Not every step in a workflow requires a frontier model. Businesses that architect their AI systems with task-appropriate model tiers will achieve significantly better economics than those routing everything through a single heavyweight model.
- The coding and software development use cases are particularly mature. SWE-Bench (real software engineering tasks), IFBench (instruction following), and the terminal use benchmark all show strong performance. For technology companies and in-house engineering teams in Southeast Asia evaluating AI-assisted development tools, Nemotron 3 Super is worth a direct evaluation.
We’ve also recently covered Anthropic’s research on AI’s actual labour market impact — which found that deployment is currently far behind theoretical capability. Nemotron 3 Super is one of several releases in early 2026 that is actively closing that gap, particularly in the agentic and autonomous workflow categories where the deployment barrier has historically been highest.
At Axient.ai, we help businesses across Singapore, Jakarta, Bangkok, and Kuala Lumpur evaluate and deploy AI tools that are genuinely ready for production — including agentic systems where the architecture decisions made now will determine long-term performance and cost.
On 5 March 2026, OpenAI released GPT-5.4 — its latest frontier model, and the one they’re positioning as the most capable option for professional work. It’s rolling out across ChatGPT (as GPT-5.4 Thinking), the API, and Codex, with a higher-performance GPT-5.4 Pro tier available for the most demanding tasks.
If you follow AI closely, you’ll notice the version number jumped from GPT-5.2 to GPT-5.4. That’s deliberate — this release absorbs the specialised coding capabilities of GPT-5.3-Codex into a single general-purpose model, consolidating what were previously separate tracks into one unified frontier model.
GPT-5.4 is a significant release, not just an incremental update. It brings together meaningful advances across reasoning, coding, computer use, and tool orchestration. For businesses in Singapore, Jakarta, Bangkok, and Kuala Lumpur that are actively evaluating or deploying AI tools, the improvements here are worth understanding beyond the headline numbers.
Here’s a clear breakdown of what’s new, what the benchmarks actually mean, and what we think matters most for business applications. The full announcement is on OpenAI’s website.
What GPT-5.4 Brings Together
The most important thing to understand about GPT-5.4 is what it consolidates. Previous OpenAI releases split capabilities across different specialised models — coding tasks went to Codex, reasoning tasks went to one model, general tasks to another. GPT-5.4 is the first release that brings all of these into a single model: strong general reasoning, leading coding ability, native computer use, and efficient tool handling.
That matters practically because it simplifies how developers and businesses build with the API. Instead of routing different task types to different models and managing the complexity that creates, GPT-5.4 handles all of it — and according to OpenAI’s benchmarks, handles most of it better than the previous specialised models did individually.
Knowledge Work: Matching Professionals at Scale
OpenAI tested GPT-5.4 on GDPval — a benchmark that tasks models with producing real professional deliverables across 44 occupations spanning the top nine industries by contribution to US GDP. Tasks include things like sales presentations, accounting spreadsheets, manufacturing diagrams, and urgent care scheduling.
GPT-5.4 matches or exceeds industry professionals in 83.0% of comparisons. GPT-5.2 sat at 70.9%. That’s a meaningful jump — and GPT-5.4 Pro reaches 82.0%, with the standard model slightly ahead on this benchmark.
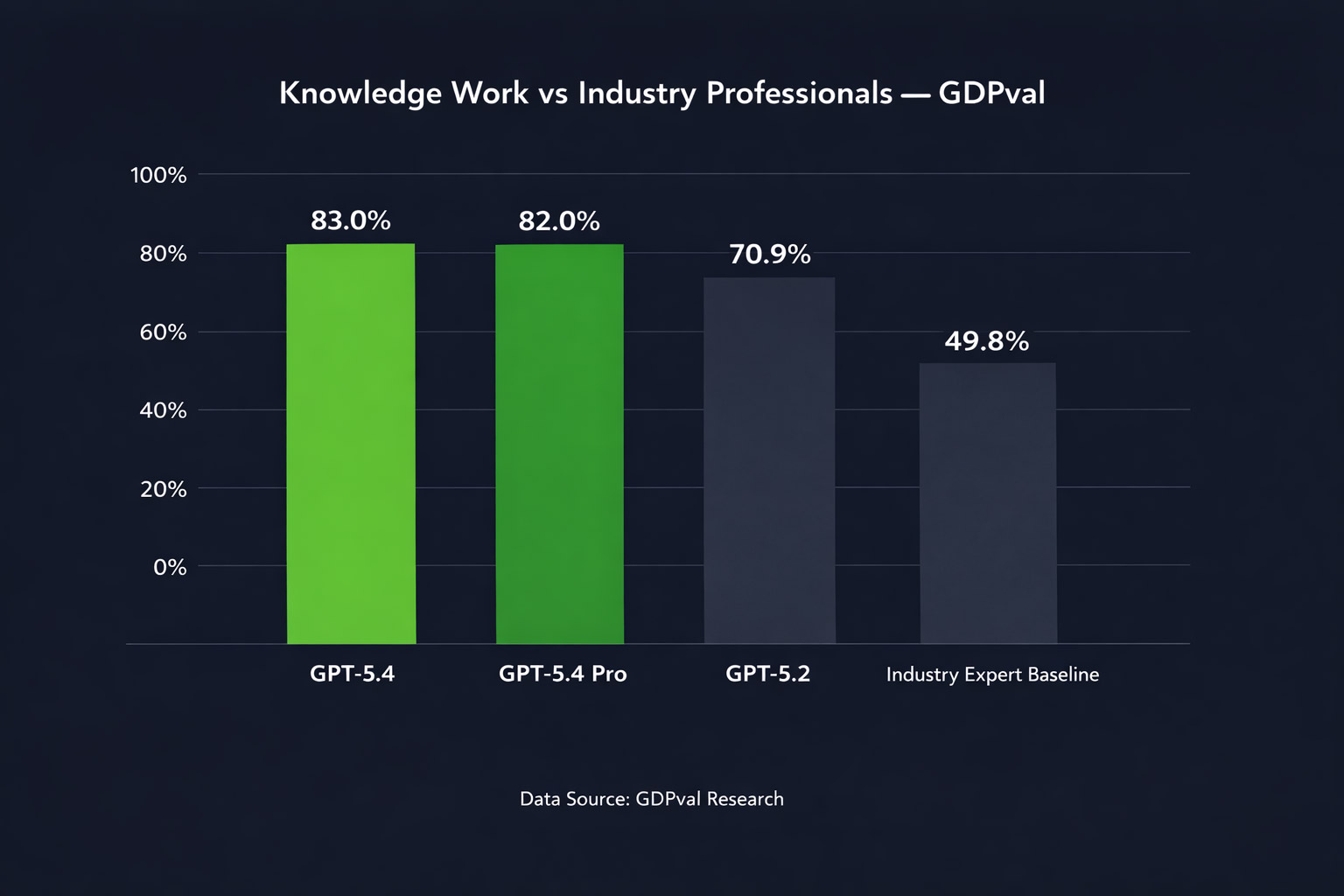
Source: OpenAI GDPval benchmark. Tasks span 44 occupations across 9 industries.
On an internal OpenAI benchmark for spreadsheet modelling tasks — specifically the kind of financial modelling a junior investment banking analyst would do — GPT-5.4 scores 87.3% versus 68.4% for GPT-5.2. Human evaluators also preferred GPT-5.4 presentations 68% of the time over GPT-5.2 ones, citing stronger aesthetics and more effective use of generated imagery.
Separately, on legal document work, Harvey’s Head of Applied Research noted GPT-5.4 scored 91% on BigLaw Bench — a benchmark for complex transactional legal analysis. These are domain-specific results, but they illustrate how broadly the capability improvements are distributing across professional work types.
Computer Use: AI That Operates Your Software
This is arguably the most consequential capability in GPT-5.4 for businesses thinking about AI automation. For the first time, OpenAI has released a general-purpose model with native computer-use capabilities — meaning the model can read screenshots, move a cursor, click buttons, fill forms, and operate software the way a human would.
Previously, this kind of capability existed only in specialised research previews. GPT-5.4 is the first mainline release where it’s production-ready and available to all API developers.
The benchmark numbers are striking. On OSWorld-Verified, which measures a model’s ability to navigate a desktop environment, GPT-5.4 achieves a 75.0% success rate — compared to 47.3% for GPT-5.2. Crucially, it also surpasses the human performance baseline of 72.4% on this benchmark.
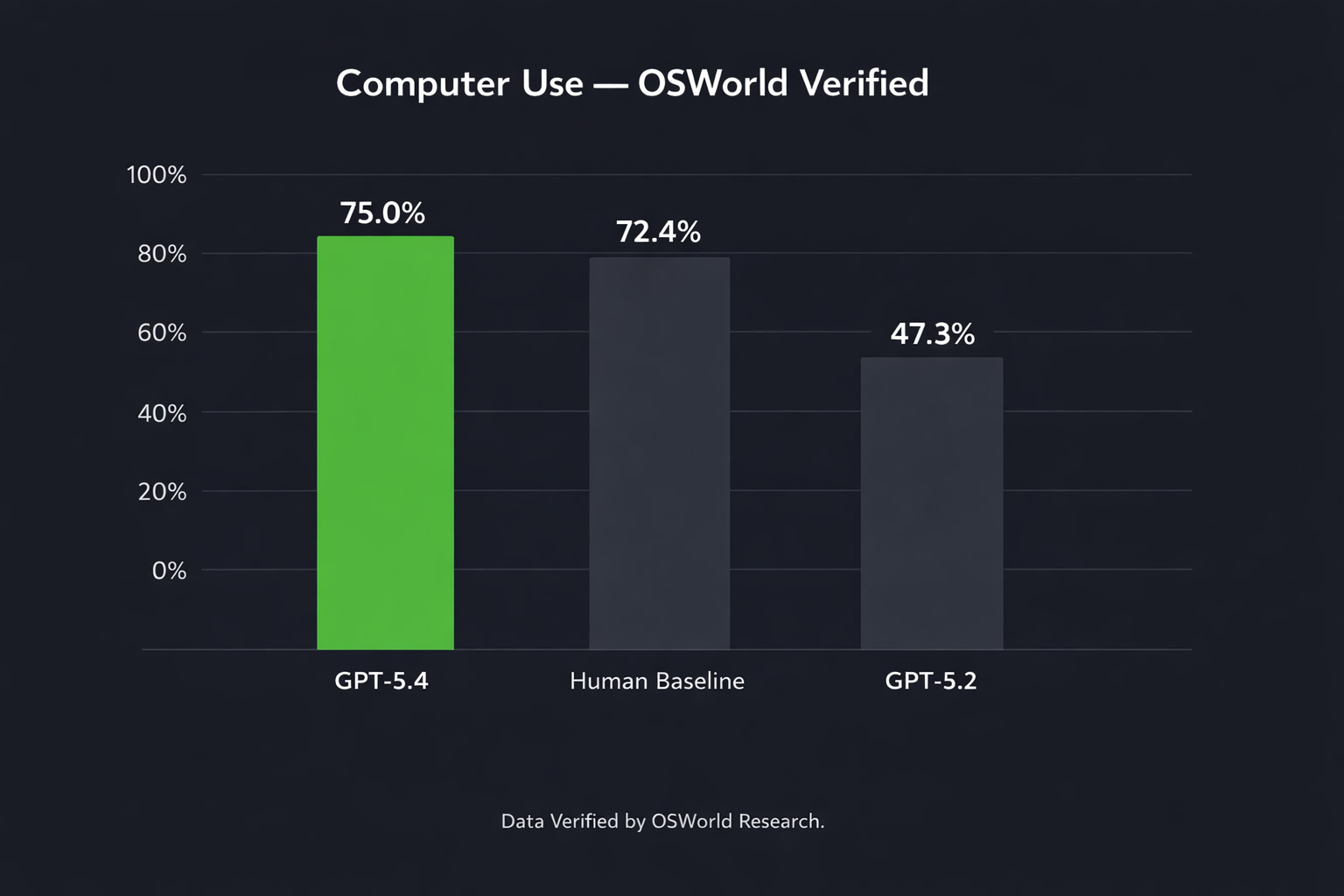
Source: OpenAI OSWorld-Verified benchmark.
On web browser tasks (WebArena-Verified), GPT-5.4 achieves a 67.3% success rate, and on Online-Mind2Web — another browser benchmark — it reaches 92.8% using screenshots alone.
One early deployment result from Mainstay, a company processing roughly 30,000 property management portal interactions, found GPT-5.4 completed tasks successfully on the first attempt 95% of the time — and 100% within three attempts — while completing sessions approximately three times faster and using around 70% fewer tokens than previous computer-use models.
For businesses in Southeast Asia thinking about AI automation of repetitive software tasks — data entry, form processing, report generation across multiple systems — this is the capability that makes that genuinely viable at scale for the first time.
Hallucinations: Measurably More Accurate
OpenAI reports that GPT-5.4 is their most factual model yet. On a set of de-identified prompts where users previously flagged factual errors, GPT-5.4’s individual claims are 33% less likely to be false, and its full responses are 18% less likely to contain any errors, compared to GPT-5.2.
We’ve covered the neuron-level research behind AI hallucinations previously — and the broader point from that research is that hallucinations are deeply rooted in how these models are trained, not simply a surface bug that gets patched away. Progress is real but incremental, and a 33% reduction in false claims, while meaningful, doesn’t mean the problem is solved. For any business use case where factual accuracy is critical, human review of AI outputs remains necessary.
Tool Use and Agentic Workflows
Tool Search: A Practical Efficiency Win
One of GPT-5.4’s most practically significant — and least discussed — improvements is tool search. When building agentic systems, developers typically give a model a list of available tools upfront. For complex integrations with many tools, this list can add tens of thousands of tokens to every single request, making workflows slow and expensive.
Tool search changes this. Instead of loading all tool definitions into the context at once, GPT-5.4 receives a lightweight index and retrieves specific tool definitions only when it needs them. In OpenAI’s own testing across 250 tasks with 36 MCP servers enabled, this reduced total token usage by 47% with no loss in accuracy.
For businesses building AI integrations across multiple platforms — connecting CRM, project management, communication tools, and databases — this is a meaningful cost and speed improvement for production deployments.
Better Web Research
GPT-5.4 Thinking improves substantially on agentic web research. On BrowseComp — a benchmark measuring persistent web browsing to find hard-to-locate information — GPT-5.4 scores 82.7%, up from GPT-5.2’s 65.8%. GPT-5.4 Pro reaches 89.3%.
In practice, this means the model is better at multi-source research tasks: synthesising information from many web pages, persisting through multiple search rounds to find specific data, and producing well-reasoned summaries. For businesses using AI for market research, competitive analysis, or due diligence workflows, this is a tangible improvement.
Mid-Response Steering
A smaller but practically useful addition: in ChatGPT, GPT-5.4 Thinking now shows a preamble outlining its approach before it starts working through a complex task. You can adjust its direction mid-response without starting over. This makes it considerably easier to get the output you actually want on long, complex queries without multiple rounds of correction.
Pricing
GPT-5.4 is priced higher per token than GPT-5.2, but OpenAI argues the greater token efficiency means the total cost of many tasks is comparable or lower in practice.
API Pricing (per million tokens)
| Model | Input | Output |
| gpt-5.2 | $1.75 | $14.00 |
| gpt-5.4 | $2.50 | $15.00 |
| gpt-5.2-pro | $21.00 | $168.00 |
| gpt-5.4-pro | $30.00 | $180.00 |
Batch and Flex processing available at half the standard rate. Priority processing at 2x.
In ChatGPT, GPT-5.4 Thinking replaces GPT-5.2 Thinking for Plus, Team, and Pro users starting today. GPT-5.2 Thinking will remain available in the legacy model picker until June 5, 2026. GPT-5.4 Pro is available on Pro and Enterprise plans.
What This Means for Businesses in Southeast Asia
Taken together, GPT-5.4 represents a meaningful step forward across four dimensions that matter for business AI deployment: the quality of professional work outputs, the ability to automate software-based tasks directly, the reliability of information, and the efficiency of agentic workflows.
The computer-use capabilities in particular open up automation possibilities that weren’t practical before — not just for tech companies, but for any business that runs repetitive tasks across web-based software. Finance teams, operations teams, marketing teams, and customer service functions in Singapore, Jakarta, Bangkok, and Kuala Lumpur all have workflows that fit this description.
That said, a few things are worth keeping in mind as you evaluate this release:
- Benchmark numbers reflect controlled testing conditions. Real-world performance on your specific tasks will vary, and piloting before scaling is always the right approach.
- Computer-use capabilities are powerful but require careful governance. An agent that can operate software can also make mistakes in software. Clear confirmation policies and human checkpoints matter.
- The hallucination improvements are real but not complete. A 33% reduction in false claims still means false claims occur. Review processes remain essential for any output that carries business or legal weight.
- The consolidation of models simplifies architecture decisions for developers, which reduces the overhead of building and maintaining AI integrations.
The pace of development across the major AI providers — OpenAI, Google, and others — continues to accelerate. We’ve covered Google’s Nano Banana 2 and NVIDIA’s autonomous network AI in recent posts. What’s emerging across all three is a consistent direction: models that don’t just answer questions, but execute real work across real software environments with increasing reliability.
At Axient.ai, we help businesses across Singapore, Jakarta, Bangkok, and Kuala Lumpur navigate exactly these decisions — evaluating which tools are ready for which use cases, and building the implementation and governance structures that make AI deployments actually work in production.
There’s a moment in every major technology shift when the tools stop being experimental and start being deployed for real. In the world of AI and telecommunications, that moment appears to have arrived.
At Mobile World Congress Barcelona in late February 2026, NVIDIA unveiled a set of tools that collectively represent the most concrete push yet toward fully autonomous telecom networks. The centrepiece is a free, open source, 30-billion-parameter AI model built specifically for telecom operations — designed not just to automate predefined tasks, but to reason through complex network problems the way an experienced engineer would.
For most businesses, telecom infrastructure sits quietly in the background — it’s what makes everything else work. But what NVIDIA is building points toward something that will affect every organisation that depends on connectivity, which at this point is every organisation. And for businesses in Singapore, Indonesia, Thailand, and Malaysia operating in one of the world’s most digitally active regions, the direction this is heading matters.
Note for CMS import: All section headings below are H2. Sub-sections are H3. The post title above is H1.
The Problem NVIDIA Is Trying to Solve
Modern telecom networks are extraordinarily complex. A single operator manages thousands of cell towers, routing systems, and configuration variables across a multi-vendor environment. When something goes wrong — a fault, a traffic surge, a configuration error — network operations centre (NOC) engineers are typically the ones diagnosing and fixing it, often manually, often in the middle of the night.
Automation has been part of telecom for years, but it’s a specific kind of automation: executing predefined workflows. Something goes wrong, a script runs, a known fix is applied. That works for known problems. What it can’t do is reason through novel situations, weigh trade-offs, or decide what action to take when the situation doesn’t match a template.
According to NVIDIA’s State of AI in Telecommunications report, network automation is now the top AI use case for investment and measurable return on investment among telecom operators globally. The appetite is clearly there. What’s been missing is the infrastructure to deliver true autonomy rather than scripted automation.
NVIDIA’s answer is an end-to-end agentic system: specialised AI models that understand telecom, agents that communicate with each other, and simulation tools that validate decisions before they touch a live network.
What NVIDIA Actually Released
The Open Nemotron Large Telco Model
The headline release is the NVIDIA Nemotron Large Telco Model (LTM) — a 30-billion-parameter open source model built on the Nemotron 3 foundation model family and fine-tuned by AdaptKey AI using open telecom datasets including industry standards and synthetic operational logs.
What makes it notable isn’t just its size. It’s that the model is specifically trained to understand telecom language and reason through real operational workflows: fault isolation across multi-vendor environments, remediation planning, change validation, rollback procedures. According to independent coverage by Winbuzzer, the model improves incident summary accuracy from roughly 20% to 60% — tripling the rate at which outputs are reliable enough to act on without human review.
Because it’s open source, operators get full transparency into how it was trained and on what data. That matters for security and compliance — operators can deploy it on-premises, within their own network, without sending sensitive operational data to a third-party cloud.
Teaching AI Agents to Think Like Engineers
Alongside the model, NVIDIA and Tech Mahindra published an open source implementation guide showing telecom operators how to fine-tune domain-specific reasoning models and build agents capable of running NOC workflows autonomously.
The approach is worth understanding. Rather than simply training a model on historical data, the guide outlines a method for creating structured “reasoning traces” — step-by-step records of how expert engineers actually diagnose and resolve incidents, including every action taken, tool used, and decision made along the way. These traces become the training examples the model learns from, so it understands not just what to do, but why a particular sequence is safe and effective.
Using NVIDIA’s NeMo-Skills pipeline, operators can fine-tune a reasoning model on these traces to create agents that approach troubleshooting with genuine engineering logic, not just pattern matching.
Blueprints for Energy and Network Configuration
NVIDIA also released two new practical blueprints — reference architectures that operators can adapt for their own environments:
- The Intent-Driven RAN Energy Efficiency Blueprint uses AI agents and synthetic network simulation to generate and test energy-saving policies for 5G radio access networks, allowing operators to reduce power consumption without risking disruption to live services.
- The Network Configuration Blueprint with Multi-Agent Orchestration deploys coordinated agents to monitor network performance, recommend and implement configuration changes, and roll them back if unintended effects are detected — all with governance documentation built in.
Both blueprints are available as open resources through GSMA’s new Open Telco AI initiative, making them accessible to operators of any size — not just the tier-1 carriers with large internal AI teams.
Real Deployments, Already Running
What gives this announcement more weight than a typical research preview is the fact that these tools are already in production.
Cassava Technologies is deploying the network configuration blueprint to build its Cassava Autonomous Network — an agentic platform managing Africa’s complex multi-vendor mobile environment. NTT DATA is using it to help a tier-1 Japanese operator handle traffic surges dynamically after outages. And Telenor Group will be the first to adopt the enhanced multi-agent version through partner BubbleRAN, targeting its maritime 5G connectivity services for ships at sea.
As CRN Asia’s coverage of MWC 2026 noted, NVIDIA’s push at this year’s Mobile World Congress was the most comprehensive AI-native telecoms vision the industry has seen — spanning autonomous operations, AI-RAN architecture, and early commitments toward 6G from more than a dozen global carriers including BT Group, Deutsche Telekom, Ericsson, Nokia, and T-Mobile.
Why This Matters Beyond Telecom
If you’re not a telecom operator, you might be wondering why this is relevant to your business. The connection is more direct than it might appear.
Agentic AI Is Becoming the Standard Model for Enterprise Automation
The architecture NVIDIA is deploying for telecom — specialised reasoning models, coordinated AI agents, closed-loop validation before action — is the same architecture being adopted across enterprise AI. What’s being proven at scale in one of the world’s most complex operational environments will become the template for how AI is deployed in logistics, manufacturing, financial services, and beyond.
This is directly connected to the broader shift toward agentic AI that we’ve been tracking closely. If you’re thinking about how AI can move from answering questions to actually executing workflows in your business, telecom’s autonomous network journey is one of the clearest roadmaps currently available.
Open Source AI Reduces the Barrier to Serious Adoption
The fact that NVIDIA is releasing a 30-billion-parameter, domain-specialised model as open source — freely available through GSMA — is significant for businesses outside of telecoms too. It signals a broader trend: high-quality, task-specific AI models are increasingly becoming accessible resources rather than proprietary advantages held by a handful of large companies.
For businesses in Southeast Asia looking to implement AI solutions — whether in Singapore, Jakarta, Bangkok, or Kuala Lumpur — this trend matters. The tools required to build genuinely capable AI systems are becoming more accessible. What increasingly differentiates outcomes is how well those tools are implemented, integrated, and governed within a specific business context.
The Reliability Question Is Central
One of the most important elements of NVIDIA’s approach here is its emphasis on closed-loop validation — testing AI decisions in simulation before they affect live systems. This is a direct response to the reliability concerns that slow AI adoption in high-stakes environments.
We’ve written before about the neuron-level mechanisms behind AI hallucinations and the kinds of over-compliance behaviours that make AI outputs unreliable in critical contexts. What NVIDIA’s telco blueprint demonstrates is one practical answer to that challenge: don’t deploy AI agents directly into live environments — build simulation layers that let agents prove their reasoning before they act. It’s a design principle worth applying well beyond telecoms.
The Bigger Picture for AI in Southeast Asia
Southeast Asia’s telecom infrastructure is expanding rapidly. Operators in Indonesia, Thailand, Malaysia, and Singapore are actively deploying 5G and preparing for the next generation of connectivity. The tools NVIDIA is releasing are available globally and immediately relevant to regional operators looking to move toward more autonomous, efficient network management.
More broadly, the pattern being established here — open models, agentic workflows, simulation-validated decisions, domain-specific fine-tuning — represents the direction enterprise AI is heading across all sectors. Businesses that understand this architecture now will be better positioned to evaluate and implement AI solutions as the tools mature.
The conversation has clearly shifted. AI is no longer being discussed as a future capability for telecoms and enterprise operations — it’s being deployed, measured, and iterated on. For businesses across the region thinking about what AI means for their own operations, the combination of smarter tools and more open access to them makes this a genuinely good moment to be making informed decisions about where and how to apply it.
At Axient.ai, we help businesses across Singapore, Jakarta, Bangkok, and Kuala Lumpur make sense of exactly these kinds of developments — and translate them into practical, well-governed AI implementations that create real business value.
If you’ve been following the AI space, you’ll know that Google’s image generation model Nano Banana had quite a moment when it launched in August 2025. Within four days of going live, it attracted 13 million new users. By October, over 5 billion images had been generated through it. It became the kind of viral product that genuinely changes how everyday people — and businesses — think about visual content.
On 26 February 2026, Google DeepMind released the next chapter: Nano Banana 2 (officially Gemini 3.1 Flash Image). It’s now rolling out across 141 countries, including Singapore, Indonesia, Thailand, and Malaysia, and it’s already the default image model across Google’s ecosystem — Gemini app, Google Search, Lens, Google Ads, and the video editing tool Flow.
This isn’t just a minor version bump. For businesses working with digital content, marketing assets, and AI-powered workflows across Southeast Asia, it represents a meaningful shift in what’s accessible, how fast it is, and what it costs. Here’s what you need to know.
What Nano Banana 2 Actually Is
Nano Banana 2 is Google’s attempt to close the gap between speed and quality in AI image generation — two things that have historically been in tension. Previous models made you choose: you could have fast and decent, or slow and excellent. Nano Banana 2 makes a credible case that you don’t have to choose anymore.
Technically, it sits between the original Nano Banana (Gemini 2.5 Flash Image) and Nano Banana Pro (Gemini 3 Pro Image) in terms of positioning, but it inherits the Pro model’s most valuable features and delivers them at Flash speed. According to Google’s own preference evaluations, it outperformed not just its predecessor but also competitors including OpenAI’s GPT-Image 1.5 and ByteDance’s Seedream 5.0 Light in overall visual quality, infographic clarity, and factual accuracy.
You can read Google’s full announcement on The Keyword blog, and the developer-focused release is covered separately at Google’s developer blog.
The Key Capabilities Worth Knowing About
Advanced World Knowledge and Real-Time Grounding
One of Nano Banana 2’s most practically useful features is its ability to draw on Gemini’s real-world knowledge base and pull from live web search to render specific subjects accurately. This means if you ask it to generate a product visual set in a specific real-world location — say, a food shot in the context of a Jakarta street market, or a corporate visual referencing the Singapore skyline — the model has actual contextual reference points to work from, rather than guessing.
For businesses running localised campaigns in Southeast Asia, this is directly relevant. The model’s grounding in real-world knowledge and search makes it far more capable of producing regionally accurate, contextually appropriate visuals than most image generators that rely entirely on training data alone.
Precision Text Rendering and Multilingual Support
Text in AI-generated images has been notoriously unreliable — a persistent frustration for anyone trying to generate marketing mockups, event graphics, social posts, or presentation slides. Nano Banana 2 addresses this directly, offering accurate, legible text rendering within images, as well as the ability to translate and localise text inside an image across multiple languages.
For agencies and brands operating across Singapore, Thailand, Indonesia, and Malaysia — where content regularly needs to work in English, Bahasa Indonesia, Thai, and Malay — this is a genuine practical improvement. Generating a single master visual and localising the text within it, rather than recreating it from scratch for each market, is a real workflow benefit.
Subject Consistency and Complex Scene Control
Nano Banana 2 can maintain character consistency across up to five characters and track up to 14 objects within a single workflow. For businesses building visual narratives — product campaigns, branded content series, storyboards — this means you can iterate on a visual concept without the model forgetting what your characters or products are supposed to look like from one image to the next.
This kind of consistency has historically been one of the hardest things to achieve with AI image generation, and it’s one of the main reasons creative teams have been cautious about using these tools for anything beyond one-off images.
Production-Ready Specs: 512px to 4K
Resolution support ranges from 512px up to full 4K, with flexible aspect ratios across the board. Whether you’re producing assets for a vertical social post, a horizontal website hero banner, a print-ready mockup, or a widescreen digital out-of-home display, the model outputs at the spec you need. According to TechCrunch’s coverage of the launch, this is among the most flexible resolution ranges available in any commercially accessible image model right now.
Where It’s Available — Including Across Southeast Asia
Nano Banana 2 is already live and rolling out as the default image model across Google’s product suite:
- Gemini app (Fast, Thinking, and Pro modes) — replacing Nano Banana Pro as the default
- Google Search — in AI Mode and via Lens, across desktop and mobile
- Google Ads — available now, powering creative suggestions in campaign creation
- Flow — Google’s video editing tool, where it’s now the default and available at zero credits
- Gemini API and AI Studio — available in preview for developers, with pricing starting at $0.045 per image at 512px
- Google Cloud / Vertex AI — available in preview
The rollout covers 141 countries and eight new languages, which includes the key Southeast Asian markets of Singapore, Indonesia, Thailand, and Malaysia. Google AI Pro and Ultra subscribers retain access to Nano Banana Pro for specialised high-fidelity tasks via the three-dot regeneration menu.
What This Means If You’re Running an AI-Powered Business
At Axient.ai, we work with businesses across Singapore, Jakarta, Bangkok, and Kuala Lumpur to implement AI solutions that create real operational value. Nano Banana 2 matters to us — and to our clients — for a few specific reasons.
The Cost of High-Quality Visual Content Just Dropped Significantly
Producing professional-grade visual assets has traditionally been time-intensive and expensive — requiring design teams, stock libraries, photography budgets, and rounds of revision. AI image generation has been changing this for a while, but the quality ceiling and the speed floor have limited how far businesses could push it in production environments.
Nano Banana 2 raises that ceiling and lowers that floor at the same time. At approximately $0.045 per image via the API at 512px resolution (with a 50% discount available through batch processing), the economics of generating large volumes of visual content shift considerably. For e-commerce businesses, digital marketers, and content teams across Southeast Asia managing campaigns at scale, this is directly relevant to budget planning and production timelines.
Visual AI Is Now Embedded in Tools Businesses Already Use
One of the practical barriers to AI adoption for many businesses isn’t capability — it’s integration. The fact that Nano Banana 2 is now the default model inside Google Ads, Google Search, and the Gemini app means businesses don’t need to adopt a separate tool or build a custom workflow to access it. If you’re already running Google Ads campaigns, you already have access to Nano Banana 2-powered creative suggestions.
For AI solution providers and digital agencies in Singapore and across the region, this also means that client conversations about visual AI are moving from “should we explore this?” to “how do we use what’s already there?”
Responsible AI and Content Provenance Are Getting Practical
One dimension of this launch that doesn’t always get the attention it deserves is the provenance work. Every image generated by Nano Banana 2 includes a SynthID watermark — Google’s invisible digital signature for AI-generated content — and is paired with C2PA Content Credentials, a standard developed collaboratively with Adobe, Microsoft, OpenAI, and Meta.
Since SynthID verification launched in November 2025, it has been used over 20 million times. As AI-generated imagery becomes more prevalent in marketing, news, and social media, having verifiable provenance baked into the generation process — rather than bolted on afterwards — matters for businesses that care about brand trust and transparency.
This is an area we think about carefully when advising clients on AI content workflows. The tools are maturing in the right direction.
The Bigger Picture for AI in Southeast Asia
Southeast Asia is one of the fastest-growing regions for digital business and AI adoption. Businesses in Singapore, Indonesia, Thailand, and Malaysia are actively building AI into their marketing, operations, customer experience, and product development. The arrival of a tool like Nano Banana 2 — capable, fast, affordable, and already embedded in platforms businesses use daily — accelerates that adoption curve.
The question for most businesses is no longer whether AI-generated visuals have a role in their content strategy. The question is how to implement them thoughtfully: with the right quality controls, the right human oversight, and the right integration into existing workflows.
That’s where having a knowledgeable AI partner makes a difference — not to hand over the keys entirely, but to help you get real value from these tools without the costly trial and error. At Axient.ai, that’s exactly what we help businesses across the region do.
Source: Google DeepMind (February 26, 2026). Nano Banana 2: Combining Pro capabilities with lightning-fast speed. The Keyword, Google Blog.