
Every week, a new headline claims AI is either destroying jobs at scale or creating an economic golden age. The reality, according to a substantial new research paper published this month by Anthropic economists Maxim Massenkoff and Peter McCrory, is considerably more measured: AI is technically capable of automating a wide range of professional tasks, but the evidence of it actually displacing workers in large numbers — so far — is limited.
The paper, titled “Labor Market Impacts of AI: A New Measure and Early Evidence”, introduces a new way of measuring AI’s real-world labour market impact, and then tests it against actual employment data from the US Current Population Survey. It’s one of the more carefully constructed analyses we’ve seen on this topic, and the findings are worth understanding in full — particularly for business leaders in Singapore, Jakarta, Bangkok, and Kuala Lumpur who are making decisions about AI adoption right now.
Here’s what it found, what it means, and what we think the right business response is.
The Core Problem With Most AI Job Predictions
Massenkoff and McCrory open with a useful caution: past predictions about technology displacing workers have a poor track record. A prominent study on job offshorability identified roughly a quarter of US jobs as vulnerable to overseas competition — but a decade later, most of those roles had grown. The researchers argue this history warrants humility when assessing AI’s likely labour market impact.
The fundamental challenge is a counterfactual problem. When COVID hit, unemployment jumped sharply almost overnight — the cause and effect were clear. AI’s impact on employment is more likely to resemble the slow diffusion of the internet or the China trade shock: gradual, uneven, and difficult to separate from other economic forces like interest rates, demographic change, and the business cycle.
Most existing research on AI exposure focuses on theoretical capability — asking what tasks an AI could plausibly perform. The Anthropic paper introduces something more useful: a measure of observed exposure, which combines theoretical capability with actual real-world usage data from Claude conversations.
Theoretical Capability vs. Real-World Usage: A Large Gap
The paper’s most striking finding isn’t about job losses at all — it’s about the gap between what AI can do and what it is actually doing.
Using task-level data from the O*NET occupational database, the researchers cross-referenced each task with two things: whether it’s theoretically possible for an AI to speed it up (using an existing academic measure called the Eloundou et al. β score), and whether Claude is actually being used to perform that task in practice (using Anthropic’s Economic Index data).
The result: 97% of observed Claude usage falls into tasks that are theoretically feasible for AI. But actual automated coverage remains a fraction of what theory suggests is possible. In Computer & Mathematics occupations — where AI usage is highest — Claude currently covers only 33% of tasks, despite theory suggesting scope for penetration across 94%.
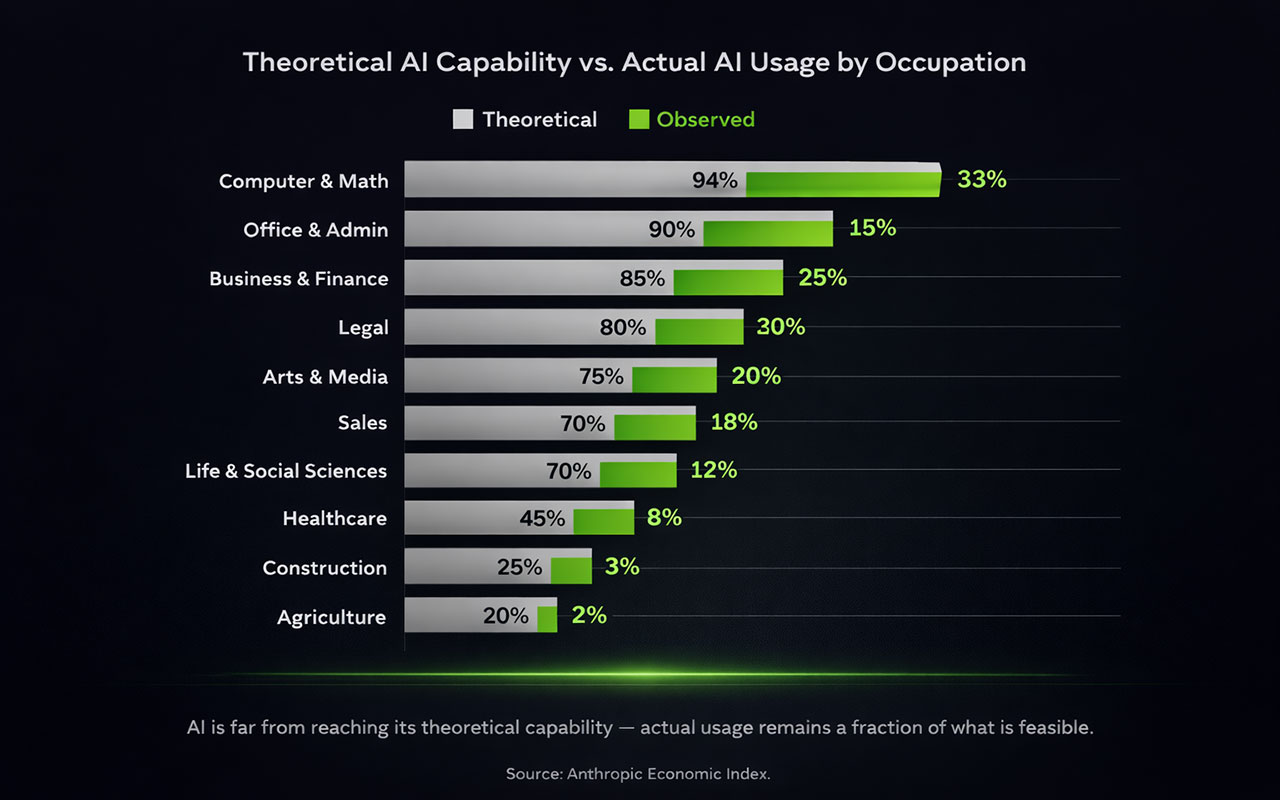
The researchers describe this gap as one of the key insights: AI deployment is constrained not just by model capability, but by legal requirements, software integration hurdles, human verification steps, and simple adoption lag. The technology is ahead of the deployment.
Which Jobs Are Most Exposed?
The paper identifies the ten most exposed occupations based on observed — not theoretical — AI coverage. The list is instructive:
| Occupation | Observed AI Exposure | Primary Automated Task |
|---|---|---|
| Computer programmers | 74.5% | Write, update, and maintain software programs |
| Customer service representatives | 70.1% | Handle customer queries and complaints |
| Data entry keyers | 67.1% | Read source documents and enter data into systems |
| Medical record specialists | 66.7% | Compile and code patient data |
| Market research analysts | 64.8% | Prepare reports and translate findings into text |
| Sales representatives | 62.8% | Contact customers and solicit orders |
| Financial and investment analysts | 57.2% | Analyse financial information for forecasting |
| Software QA analysts and testers | 51.9% | Modify software to correct errors |
| Information security analysts | 48.6% | Perform risk assessments |
| Computer user support specialists | 46.8% | Answer user inquiries about software |
Source: Massenkoff & McCrory (2026), Anthropic Economic Index. Top 10 most exposed occupations by observed AI task coverage.
What’s notable about this list is who is on it. These are not low-wage, low-skill roles. They are educated, well-paid, primarily white-collar jobs — exactly the segment that previous technology disruptions tended to spare. The paper confirms this with demographic data: workers in the most exposed professions earn on average 47% more per hour than those with zero AI exposure, are more likely to hold graduate degrees, and are more likely to be female.
At the other end, 30% of workers have zero measurable AI exposure. This group includes cooks, motorcycle mechanics, bartenders, and lifeguards — roles involving physical presence, manual dexterity, or real-time social interaction that current AI tools cannot replicate.
What the Employment Data Actually Shows
Here is where the paper delivers its most important finding, and where it differs most sharply from the more alarming commentary around AI and jobs.
Using US unemployment data from the Current Population Survey, the researchers tracked unemployment trends for two groups since 2016: workers in the top quartile of AI exposure and workers with zero AI exposure. If AI were significantly displacing workers, you would expect the exposed group’s unemployment rate to rise relative to the unexposed group after ChatGPT’s release in late 2022.
It hasn’t. The average change in the gap between the two groups since ChatGPT’s release is small and statistically indistinguishable from zero. As the researchers put it, the effect is there but cannot be separated from noise.
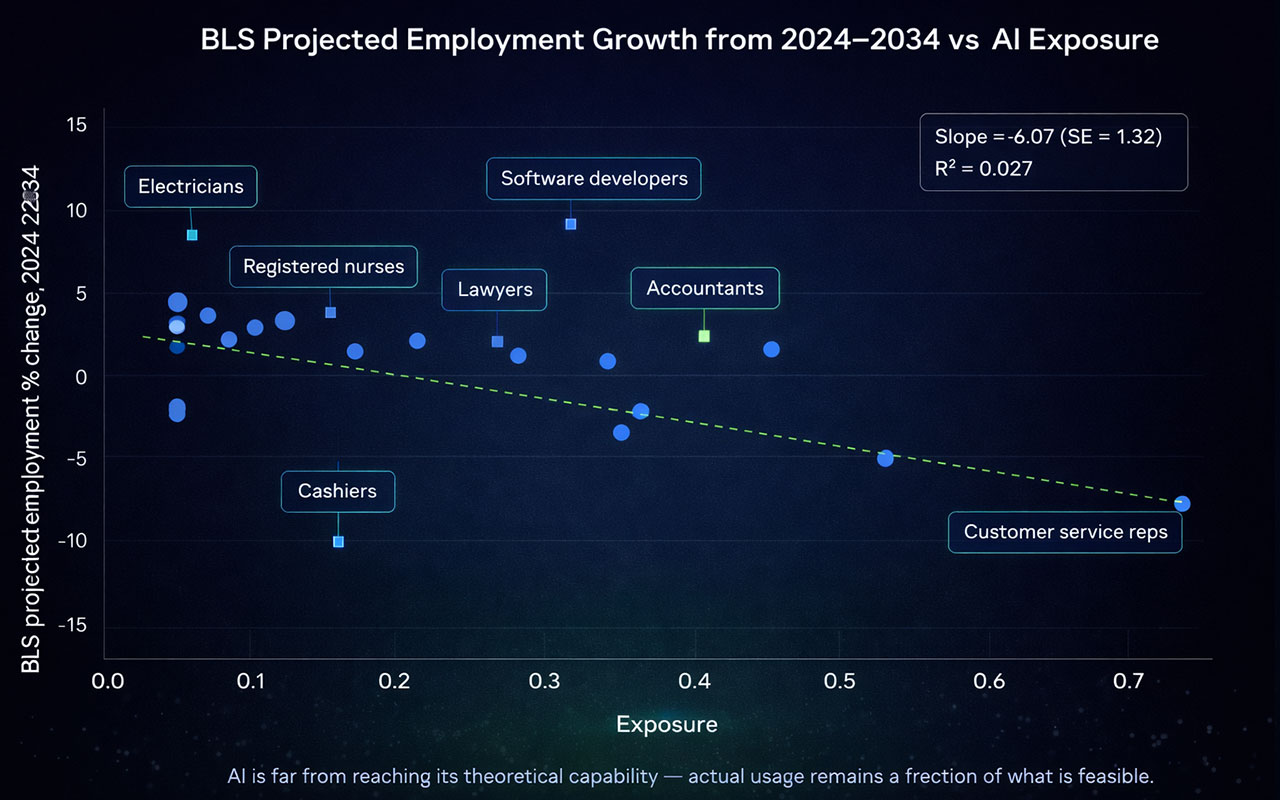
The researchers are careful about what this does and doesn’t mean. The framework can detect a differential unemployment increase of roughly 1 percentage point or more — so smaller effects could be occurring without showing up. And they note that unemployment is a lagging indicator: a labour market adjusting gradually through slower hiring and attrition might not produce a visible spike in unemployment even if real displacement is occurring.
The Young Worker Signal
The one area where the data shows something more concerning is hiring rates among workers aged 22 to 25. The researchers tracked how many young workers were starting new jobs in high-exposure versus low-exposure occupations each month.
From 2024 onward, entry rates into the most exposed occupations began declining relative to less exposed ones. The estimated drop in the job-finding rate for young workers entering high-exposure roles in the post-ChatGPT period is approximately 14% — though the researchers note this is just barely statistically significant and there are alternative explanations (young workers may be staying in existing roles, pursuing further education, or entering a different sector).
This finding echoes separate research from Brynjolfsson et al. (2025), which found a 6–16% decline in employment in exposed occupations among 22–25-year-olds, primarily driven by slowed hiring rather than increased layoffs.
The practical implication: if AI is having an early employment effect, it appears to be showing up not as mass layoffs of existing workers, but as a reduced need to hire new graduates into roles that AI is beginning to cover. Entry-level positions in knowledge work are where the early signal is clearest.
What It Means for Jobs Across Southeast Asia
A few important caveats before drawing implications for Singapore, Jakarta, Bangkok, and Kuala Lumpur. The Anthropic paper uses US data — Claude usage patterns, US occupational classifications, and US unemployment statistics. The dynamics in Southeast Asian labour markets are different: different regulatory environments, different levels of AI adoption, different occupational structures, and different wage levels that affect the economics of automation decisions.
That said, the directional findings are likely to apply broadly:
- White-collar knowledge work is where AI exposure is highest, not low-wage manual roles. In markets where companies are expanding professional services capacity — finance, legal, customer operations, data analysis — AI exposure is meaningful and growing.
- The gap between what AI can do and what businesses are actually deploying remains large. This suggests the next two to three years will be characterised by increasing deployment, not a sudden plateau. The question is the pace.
- Young workers entering the labour market may face a more competitive environment for entry-level knowledge work roles. This matters for workforce planning, graduate hiring pipelines, and skills development policy.
- The absence of large unemployment effects so far does not mean the risk has passed. The researchers explicitly frame this as an early-warning monitoring framework — the current findings are the baseline, not the conclusion.
What This Means for Your Business
For business leaders actively thinking about AI adoption, three things stand out from this research.
First, deployment gaps are opportunities. The data shows that even in the most exposed sectors, actual AI usage covers only a fraction of what’s theoretically possible. Businesses that are building systematic AI workflows now — rather than ad hoc tool use — are likely to see compounding productivity advantages relative to those that aren’t.
Second, the entry-level hiring signal is worth watching. If AI is reducing the need to hire junior analysts, junior coders, and junior customer service roles, the implications for team structure are real. Businesses that plan their talent pipelines around the assumption that the same ratio of junior-to-senior roles makes sense as it did three years ago may find themselves structurally overstaffed at the entry level.
Third, the framing of ‘jobs destroyed vs. jobs created’ is probably the wrong lens. The more useful question for most businesses is which tasks within existing roles are being covered by AI, at what depth of automation, and what that means for how those roles should be defined and resourced. That’s a workflow and operating model question, not a headcount question.
We’ve written recently about the computer-use capabilities in GPT-5.4 and NVIDIA’s agentic AI work for autonomous systems. The Anthropic paper provides useful economic context for both: the capabilities are advancing faster than deployment, which means businesses that are actively building implementation capacity now have a genuine window of competitive advantage before adoption becomes table stakes.
At Axient.ai, we help businesses across Singapore, Jakarta, Bangkok, and Kuala Lumpur work through exactly these questions — from identifying where AI exposure is genuinely high in your specific workflows, to building the governance and implementation structures that convert that exposure into productivity rather than disruption.
If you’ve used AI tools in your business — for content, customer support, research, or internal workflows — you’ve probably encountered the problem firsthand. The model confidently gives you an answer that turns out to be completely wrong. A made-up statistic. A non-existent product feature. A reference to a case study that never happened.
This is what the AI world calls a hallucination, and it’s one of the biggest reasons businesses remain cautious about deploying AI at scale.
Now, a new piece of research from Tsinghua University has done something genuinely interesting: instead of looking at hallucinations from a big-picture perspective — training data, model design, feedback processes — the researchers went microscopic. They looked inside the neural network itself and asked: which specific neurons are actually responsible for hallucinations?
The paper, “H-Neurons: On the Existence, Impact, and Origin of Hallucination-Associated Neurons in LLMs“, published in December 2025, is one of the most detailed explorations yet of hallucination at the computational level. And for businesses working with AI, the findings are worth understanding — even if you’re not a machine learning engineer.
Why Hallucinations Have Been So Hard to Fix
Before getting into the research findings, it’s worth quickly recapping why hallucinations are such a persistent problem.
Most AI language models are trained on enormous amounts of text, and they learn to predict what words or sentences should come next. This makes them very good at producing fluent, coherent-sounding output. But fluency and factual accuracy are not the same thing.
Previous research has pointed to several contributing factors: gaps and biases in training data, training methods that reward confident answers rather than honest uncertainty, and the way AI generates text one token at a time, which means a small error early on can snowball into a bigger one. Models like GPT-3.5 have been shown to hallucinate in roughly 40% of citation-based fact checks, and even GPT-4 comes in around 28.6%, according to a comparative analysis published in the Journal of Medical Internet Research.
What’s been largely missing from the conversation is a neuron-level explanation. What’s actually happening inside the model when it hallucinates? That’s the gap this new research tries to fill.
What the Research Found: Meet the H-Neurons
The Tsinghua team identified what they call H-Neurons — a very small subset of neurons inside an AI model’s feedforward networks that are strongly associated with hallucinations.
Here’s what makes this finding striking: these neurons make up less than 0.1% of all the neurons in a model. In some of the larger models tested, the proportion was as low as 0.01%. Despite being such a tiny fraction of the overall network, this group of neurons carries enough signal to reliably predict whether the model is about to produce a hallucinated response or a factually accurate one.
The researchers tested this across six different AI models — including models from the Mistral, Gemma, and Llama families — and found that classifiers built on these H-Neurons consistently outperformed classifiers built on randomly selected neurons, often by more than 10 percentage points in accuracy.
Even more significantly, the neurons identified from one type of question (general trivia) continued to predict hallucinations when tested on completely different datasets — including biomedical questions (BioASQ) and questions about entirely made-up entities that couldn’t possibly exist in any training data. That kind of generalization suggests these neurons aren’t just picking up on a quirk in one dataset. They seem to capture something fundamental about how hallucinations form.
It’s Not Just About Getting Facts Wrong
Perhaps the most counterintuitive part of the research is what happens when the researchers deliberately manipulated these neurons.
They ran a series of controlled experiments where they artificially amplified or suppressed H-Neuron activity during inference — while the model was generating a response — without retraining the model at all. And what they found was revealing.
When H-Neurons were amplified, models didn’t just become more likely to hallucinate facts. They became more compliant across the board. Specifically:
- They were more likely to accept and answer questions built on false premises, rather than correcting them.
- They were more likely to agree with deliberately misleading information provided in a prompt.
- They were more likely to change a previously correct answer when a user pushed back — even when the original answer was right.
- They were more likely to comply with harmful or inappropriate instructions.
Conversely, suppressing these neurons made the models more resistant across all four of those dimensions.
What this suggests is that hallucinations aren’t an isolated “fact-checking failure.” They appear to be one symptom of a broader tendency the researchers call over-compliance: the model’s inclination to give people what they seem to want, even when doing so means sacrificing accuracy, safety, or integrity. In other words, the model behaves a little like a people-pleaser — prioritizing the appearance of a helpful answer over the reality of whether that answer is true.
Where Do These Neurons Come From?
A natural follow-up question is: when do these neurons develop? Are they introduced during fine-tuning — the stage where a base model is refined with human feedback and instruction-following data — or are they already there in the underlying pre-trained model?
The research team’s answer is fairly clear: H-Neurons are present before fine-tuning begins.
When they took classifiers trained on instruction-tuned models and applied them directly to the original base models, the classifiers still worked. The neurons still predicted hallucinations, even in models that had never been fine-tuned. And when they looked at how much these specific neurons changed during the fine-tuning process, they found that H-Neurons tend to remain relatively stable — they show less parameter change than the average neuron in the network.
This tells us something important about where the hallucination problem actually sits. It isn’t primarily introduced by the alignment or instruction-tuning process. It appears to be baked in from the start, during the base pre-training phase, as a consequence of training a model to predict the next token in a sequence without any mechanism to distinguish between factually correct and incorrect continuations.
This finding aligns with theoretical work on why hallucinations may be an inherent feature of how language models learn, rather than an implementation bug that can simply be patched away. A paper titled “Why Language Models Hallucinate”by researchers including Adam Kalai and Santosh Vempala argues from a learning-theory perspective that hallucinations are in some sense inevitable given the structure of next-token prediction training. The H-Neuron research provides empirical, neuron-level evidence that supports this view.
What This Means for Businesses Using AI
So what should you actually take away from this if you’re a business leader, marketing manager, or digital transformation lead thinking about AI deployment?
1. Hallucinations Are Structural, Not Just Accidental
One common misconception is that hallucinations are a bug that will eventually be engineered away entirely as models get bigger and better. This research suggests the reality is more complicated. These behaviours appear to be rooted in the fundamental architecture of how models are trained, not in a surface-level flaw that can be patched. That doesn’t mean progress isn’t being made — it is — but it does mean that building AI systems for your business should involve a realistic view of where these risks live, not an assumption that they’ll disappear on their own.
2. Compliance and Hallucination Are Two Sides of the Same Coin
The link between over-compliance and hallucination is particularly relevant for business applications. If your AI system is configured to be maximally helpful and agreeable — which is often the default for customer-facing or assistant tools — it may also be more susceptible to both hallucinating and to going along with user inputs that contain errors or bad assumptions. Understanding this trade-off matters when you’re designing how your AI tools interact with customers, staff, or data.
3. Detection Is Getting More Precise
On the more positive side, this research opens a path toward much better hallucination detection — not just at the output level, but at the generation level. If you can identify which neurons are active during a response, you may be able to flag high-risk outputs in real time, before they reach an end user. This kind of signal could eventually be built into AI deployment infrastructure as a quality control layer, which is genuinely useful for any business where factual accuracy matters.
4. Fine-Tuning Alone Won’t Solve This
Many organisations ask whether they can fine-tune their way out of hallucination problems — training a model on their own data and use cases to make it more reliable. The evidence here suggests fine-tuning has limits. If the underlying neurons driving hallucinations are largely unchanged by the fine-tuning process, custom training alone is unlikely to eliminate the risk. It may still improve performance meaningfully, but it needs to be paired with thoughtful system design, output validation, and human review processes.
The Bigger Picture
Research like this represents a genuine shift in how the AI field approaches reliability. For years, the conversation about hallucinations has focused on data quality, model scale, and alignment processes. This work adds a new layer: the ability to look inside the model and identify specific computational structures tied to specific failure modes.
That’s significant not just for researchers but for the broader ecosystem of tools, platforms, and applications built on top of large language models. As this kind of interpretability research matures, it will likely feed into better monitoring tools, smarter deployment guidelines, and more nuanced conversations about where AI can and can’t be trusted to operate autonomously.
At Axient.ai, we think this kind of research matters for anyone making real decisions about AI implementation. The organisations that will get the most value from AI aren’t necessarily the ones that move fastest — they’re the ones that understand what these systems actually do, where they’re reliable, and where they need oversight. Findings like these give us a clearer and more honest picture of both.
Source: Gao et al. (2025). H-Neurons: On the Existence, Impact, and Origin of Hallucination-Associated Neurons in LLMs. arXiv:2512.01797.