

On 5 March 2026, OpenAI released GPT-5.4 — its latest frontier model, and the one they’re positioning as the most capable option for professional work. It’s rolling out across ChatGPT (as GPT-5.4 Thinking), the API, and Codex, with a higher-performance GPT-5.4 Pro tier available for the most demanding tasks.
If you follow AI closely, you’ll notice the version number jumped from GPT-5.2 to GPT-5.4. That’s deliberate — this release absorbs the specialised coding capabilities of GPT-5.3-Codex into a single general-purpose model, consolidating what were previously separate tracks into one unified frontier model.
GPT-5.4 is a significant release, not just an incremental update. It brings together meaningful advances across reasoning, coding, computer use, and tool orchestration. For businesses in Singapore, Jakarta, Bangkok, and Kuala Lumpur that are actively evaluating or deploying AI tools, the improvements here are worth understanding beyond the headline numbers.
Here’s a clear breakdown of what’s new, what the benchmarks actually mean, and what we think matters most for business applications. The full announcement is on OpenAI’s website.
What GPT-5.4 Brings Together
The most important thing to understand about GPT-5.4 is what it consolidates. Previous OpenAI releases split capabilities across different specialised models — coding tasks went to Codex, reasoning tasks went to one model, general tasks to another. GPT-5.4 is the first release that brings all of these into a single model: strong general reasoning, leading coding ability, native computer use, and efficient tool handling.
That matters practically because it simplifies how developers and businesses build with the API. Instead of routing different task types to different models and managing the complexity that creates, GPT-5.4 handles all of it — and according to OpenAI’s benchmarks, handles most of it better than the previous specialised models did individually.
Knowledge Work: Matching Professionals at Scale
OpenAI tested GPT-5.4 on GDPval — a benchmark that tasks models with producing real professional deliverables across 44 occupations spanning the top nine industries by contribution to US GDP. Tasks include things like sales presentations, accounting spreadsheets, manufacturing diagrams, and urgent care scheduling.
GPT-5.4 matches or exceeds industry professionals in 83.0% of comparisons. GPT-5.2 sat at 70.9%. That’s a meaningful jump — and GPT-5.4 Pro reaches 82.0%, with the standard model slightly ahead on this benchmark.
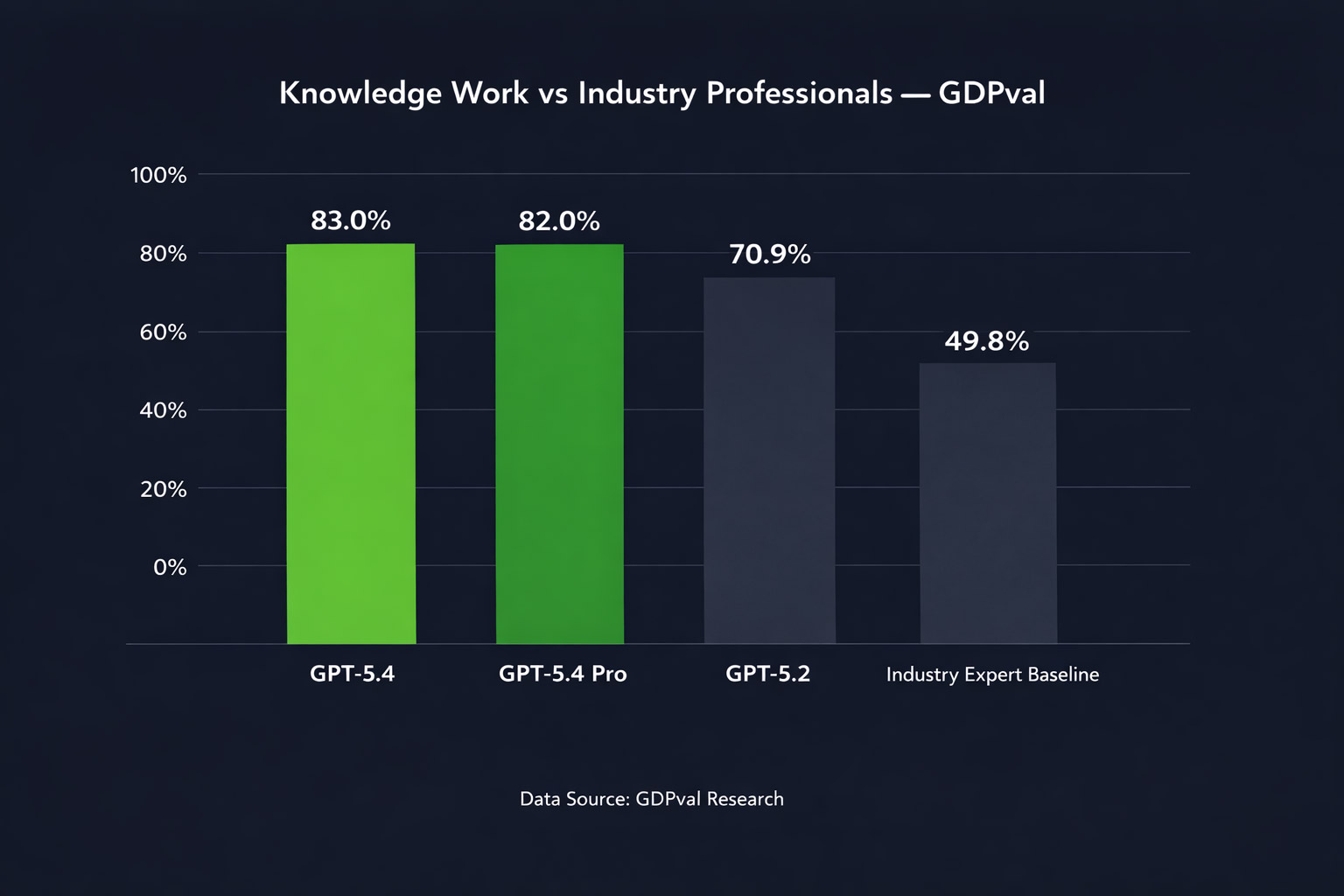
Source: OpenAI GDPval benchmark. Tasks span 44 occupations across 9 industries.
On an internal OpenAI benchmark for spreadsheet modelling tasks — specifically the kind of financial modelling a junior investment banking analyst would do — GPT-5.4 scores 87.3% versus 68.4% for GPT-5.2. Human evaluators also preferred GPT-5.4 presentations 68% of the time over GPT-5.2 ones, citing stronger aesthetics and more effective use of generated imagery.
Separately, on legal document work, Harvey’s Head of Applied Research noted GPT-5.4 scored 91% on BigLaw Bench — a benchmark for complex transactional legal analysis. These are domain-specific results, but they illustrate how broadly the capability improvements are distributing across professional work types.
Computer Use: AI That Operates Your Software
This is arguably the most consequential capability in GPT-5.4 for businesses thinking about AI automation. For the first time, OpenAI has released a general-purpose model with native computer-use capabilities — meaning the model can read screenshots, move a cursor, click buttons, fill forms, and operate software the way a human would.
Previously, this kind of capability existed only in specialised research previews. GPT-5.4 is the first mainline release where it’s production-ready and available to all API developers.
The benchmark numbers are striking. On OSWorld-Verified, which measures a model’s ability to navigate a desktop environment, GPT-5.4 achieves a 75.0% success rate — compared to 47.3% for GPT-5.2. Crucially, it also surpasses the human performance baseline of 72.4% on this benchmark.
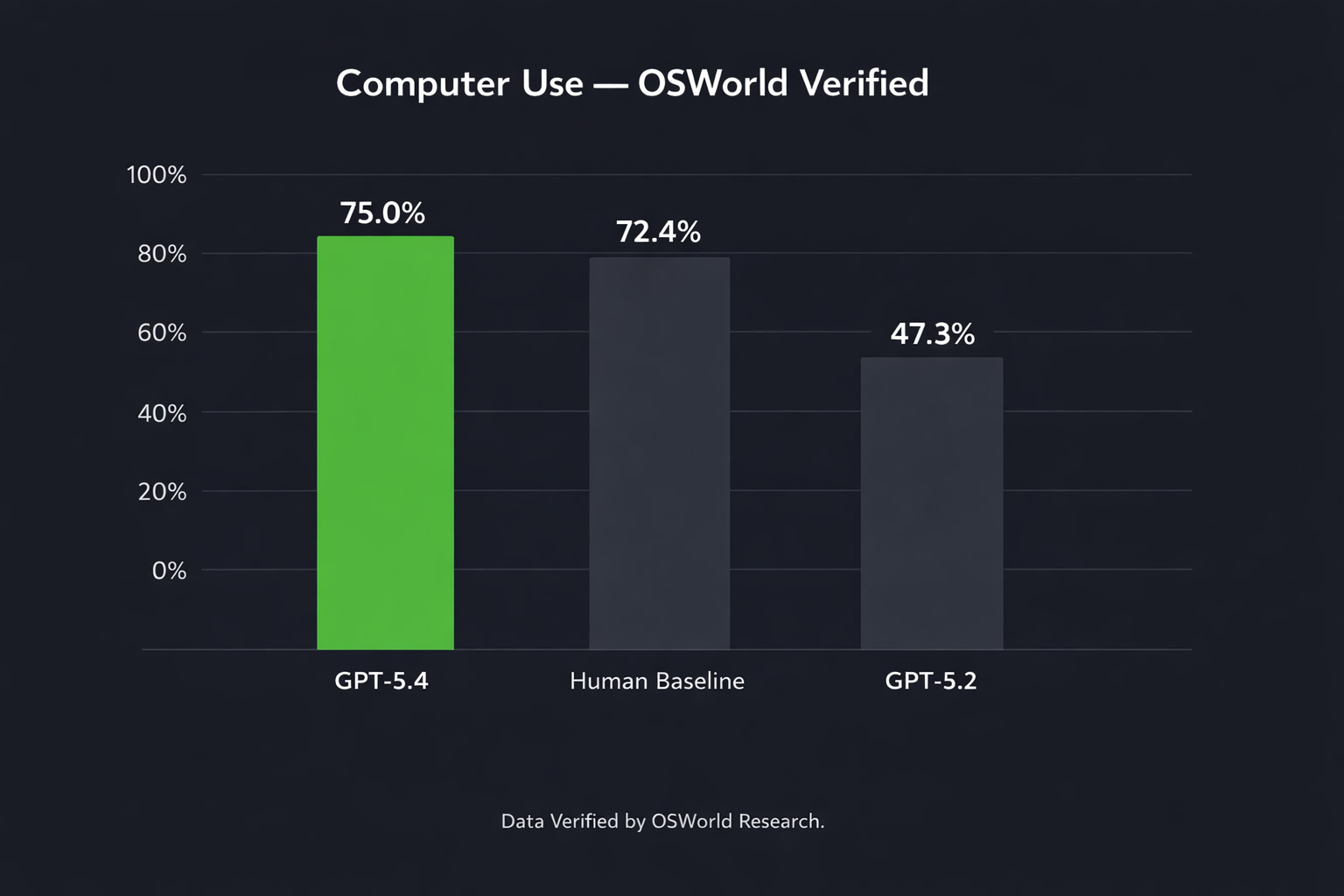
Source: OpenAI OSWorld-Verified benchmark.
On web browser tasks (WebArena-Verified), GPT-5.4 achieves a 67.3% success rate, and on Online-Mind2Web — another browser benchmark — it reaches 92.8% using screenshots alone.
One early deployment result from Mainstay, a company processing roughly 30,000 property management portal interactions, found GPT-5.4 completed tasks successfully on the first attempt 95% of the time — and 100% within three attempts — while completing sessions approximately three times faster and using around 70% fewer tokens than previous computer-use models.
For businesses in Southeast Asia thinking about AI automation of repetitive software tasks — data entry, form processing, report generation across multiple systems — this is the capability that makes that genuinely viable at scale for the first time.
Hallucinations: Measurably More Accurate
OpenAI reports that GPT-5.4 is their most factual model yet. On a set of de-identified prompts where users previously flagged factual errors, GPT-5.4’s individual claims are 33% less likely to be false, and its full responses are 18% less likely to contain any errors, compared to GPT-5.2.
We’ve covered the neuron-level research behind AI hallucinations previously — and the broader point from that research is that hallucinations are deeply rooted in how these models are trained, not simply a surface bug that gets patched away. Progress is real but incremental, and a 33% reduction in false claims, while meaningful, doesn’t mean the problem is solved. For any business use case where factual accuracy is critical, human review of AI outputs remains necessary.
Tool Use and Agentic Workflows
Tool Search: A Practical Efficiency Win
One of GPT-5.4’s most practically significant — and least discussed — improvements is tool search. When building agentic systems, developers typically give a model a list of available tools upfront. For complex integrations with many tools, this list can add tens of thousands of tokens to every single request, making workflows slow and expensive.
Tool search changes this. Instead of loading all tool definitions into the context at once, GPT-5.4 receives a lightweight index and retrieves specific tool definitions only when it needs them. In OpenAI’s own testing across 250 tasks with 36 MCP servers enabled, this reduced total token usage by 47% with no loss in accuracy.
For businesses building AI integrations across multiple platforms — connecting CRM, project management, communication tools, and databases — this is a meaningful cost and speed improvement for production deployments.
Better Web Research
GPT-5.4 Thinking improves substantially on agentic web research. On BrowseComp — a benchmark measuring persistent web browsing to find hard-to-locate information — GPT-5.4 scores 82.7%, up from GPT-5.2’s 65.8%. GPT-5.4 Pro reaches 89.3%.
In practice, this means the model is better at multi-source research tasks: synthesising information from many web pages, persisting through multiple search rounds to find specific data, and producing well-reasoned summaries. For businesses using AI for market research, competitive analysis, or due diligence workflows, this is a tangible improvement.
Mid-Response Steering
A smaller but practically useful addition: in ChatGPT, GPT-5.4 Thinking now shows a preamble outlining its approach before it starts working through a complex task. You can adjust its direction mid-response without starting over. This makes it considerably easier to get the output you actually want on long, complex queries without multiple rounds of correction.
Pricing
GPT-5.4 is priced higher per token than GPT-5.2, but OpenAI argues the greater token efficiency means the total cost of many tasks is comparable or lower in practice.
API Pricing (per million tokens)
| Model | Input | Output |
| gpt-5.2 | $1.75 | $14.00 |
| gpt-5.4 | $2.50 | $15.00 |
| gpt-5.2-pro | $21.00 | $168.00 |
| gpt-5.4-pro | $30.00 | $180.00 |
Batch and Flex processing available at half the standard rate. Priority processing at 2x.
In ChatGPT, GPT-5.4 Thinking replaces GPT-5.2 Thinking for Plus, Team, and Pro users starting today. GPT-5.2 Thinking will remain available in the legacy model picker until June 5, 2026. GPT-5.4 Pro is available on Pro and Enterprise plans.
What This Means for Businesses in Southeast Asia
Taken together, GPT-5.4 represents a meaningful step forward across four dimensions that matter for business AI deployment: the quality of professional work outputs, the ability to automate software-based tasks directly, the reliability of information, and the efficiency of agentic workflows.
The computer-use capabilities in particular open up automation possibilities that weren’t practical before — not just for tech companies, but for any business that runs repetitive tasks across web-based software. Finance teams, operations teams, marketing teams, and customer service functions in Singapore, Jakarta, Bangkok, and Kuala Lumpur all have workflows that fit this description.
That said, a few things are worth keeping in mind as you evaluate this release:
- Benchmark numbers reflect controlled testing conditions. Real-world performance on your specific tasks will vary, and piloting before scaling is always the right approach.
- Computer-use capabilities are powerful but require careful governance. An agent that can operate software can also make mistakes in software. Clear confirmation policies and human checkpoints matter.
- The hallucination improvements are real but not complete. A 33% reduction in false claims still means false claims occur. Review processes remain essential for any output that carries business or legal weight.
- The consolidation of models simplifies architecture decisions for developers, which reduces the overhead of building and maintaining AI integrations.
The pace of development across the major AI providers — OpenAI, Google, and others — continues to accelerate. We’ve covered Google’s Nano Banana 2 and NVIDIA’s autonomous network AI in recent posts. What’s emerging across all three is a consistent direction: models that don’t just answer questions, but execute real work across real software environments with increasing reliability.
At Axient.ai, we help businesses across Singapore, Jakarta, Bangkok, and Kuala Lumpur navigate exactly these decisions — evaluating which tools are ready for which use cases, and building the implementation and governance structures that make AI deployments actually work in production.


